Some basic understandings
Q: 有关fragment shader中接收vertex shader穿过来的属性的问题:fragment shader是基于屏幕像素为基本单位操作的,而vertex shader是基于顶点操作。二者基于的对象不一样,那么在这里数据是怎样传输的呢?和插值有关吗?
A:在图形渲染管线中,Vertex Shader 以顶点为单位输出属性,但这些属性并不会直接传递给 Fragment Shader。渲染的核心几何单位是三角形,顶点输出的属性实际上被记录为三角形的顶点属性。在光栅化阶段,GPU 以三角形为单位生成 fragment,这里的fragment可以被理解为根据屏幕像素,把一个由线组成的三角形打散为碎片,每个碎片中的属性是根据三个顶点的属性进行插值得到(重心坐标插值,如 UV、法线等)。Fragment Shader 实际接收到的是每个 fragment ;对于不需要插值的离散数据(如 material ID),可使用 flat 修饰符使整个三角形内的 fragment 接收相同的值。
从这个角度上看,就能很容易的理解深度测试的机理:实际上对不同三角形上的fragment,是可能对应到同一个屏幕上的像素的。但实际绘制的只有一个,因此就需要对他们进行取舍。直观的,我们可以在fragment执行完毕之后做检测,根据z-test结果剔除深度比较大的fragment。当然,在fragment之前我们就已经能够得到有关fragment的信息,因此在这里就可以做z-test(Early-Z),使部分fragment根本不需要进入shader。
Early-Z 的本质是“用深度尽早淘汰不可见 fragment 以避免无意义的 Fragment Shader 执行”,它是现代 GPU 性能优化中最关键的机制之一,但会在 fragment 存在不确定性(如 discard、写深度)时退化为 Late-Z。
有关渲染方程的理解
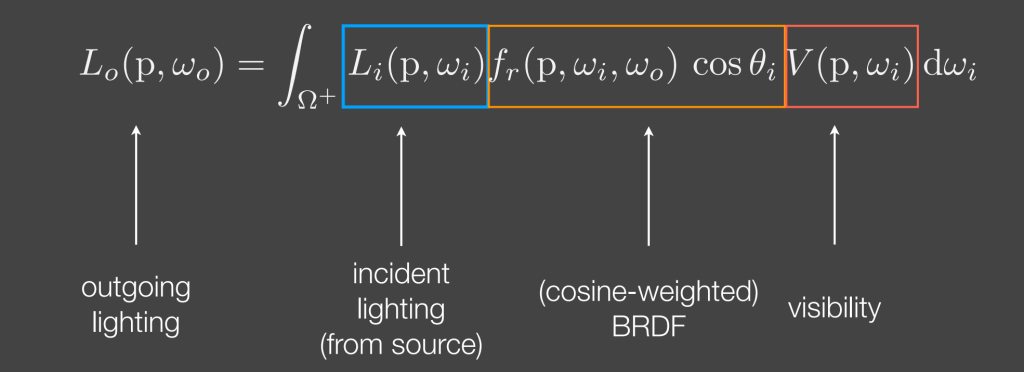
在实时渲染的方程中,Lo = Li * BRDF * visibility。注意这个渲染方程实际上对应了3d空间里的一个点,但一般都是为了处理一个fragment的。
Li项(incident lighting 入射光线),也就是代表不同方向上对应光照的强度(辐照度 radiance)
Environment Lighting based on IBL 是一个工程上近似,防止逐像素积分的做法。本质上是:假设光源在无穷远,通过采样一个cubeMap或者一个球来得到Li项。同时通过预计算处理,加速积分。
在 IBL 中,原始环境贴图表示的是方向相关的入射辐射度 。为了避免在 fragment 中对渲染方程进行实时积分,实时渲染并不直接使用该贴图,而是通过预计算将积分拆分:对 diffuse 部分直接存储 Li 与 cosine 项卷积后的积分结果;对 specular 部分则将环境相关的积分结果存入预滤波环境贴图,将材质相关的积分结果存入 BRDF 查找表,从而以查表方式近似完整积分。当然在这个过程中,默认含有visibilty = 1的假设保证这一项不影响积分加速,同时通过拆分保证把环境项和材质项解耦。
BRDF:BRDF 描述的是:描述入射方向 的能量,有多少会被反射到出射方向 。
这一项是和物体的材质属性相关,在物理上很复杂,但在Cook–Torrance microfacet BRDF就表现为metallic,roughness这些参数,也就是一个高度参数化的物理近似模型。
visibility是决定光源可见性的一项。考虑到不是所有方向的光源都是完全可见的,因此这一项和遮挡有关的项也组成实时渲染的一部分。
Q:shadow mapping的问题
Z标准问题
- 透视投影的projection matrix会把三角形往远平面推,导致这里的Z值和实际世界空间的距离不一样。因此在fragment shader使用shadow map的时候,需要统一使用Z或者世界空间距离。
Shadow acne
- Shadow acne 的本质在于 shadow map 使用单个离散深度(一般为这个区域内的最小深度)来近似表示光源视角下的一块连续几何区域,而该区域内真实表面的深度是连续变化的。当 fragment 从相机视角重投影到光源空间并与 shadow map 中的深度进行比较时,由于两次光栅化与数值精度差异,同一表面上的不同 fragment 可能得到略大于或略小于该离散深度值,从而导致部分 fragment 被错误地判定为被自身遮挡,形成自遮挡。
- 可以想象,假如光线的方向近似于平面平行,那么一个阴影像素对应的实际空间范围将会非常巨大,在这种情况下,会出现极其严重的问题。反之,垂直的情况下问题较小,因为相对来说一个像素的覆盖范围变小了。
- 解决方式:bias容差,容忍小范围内的自遮挡问题。这个bias可能根据光源角度等参数变化,比如更斜的光的bias可能就更大。问题:detached shadow(不接触的阴影,又叫peter panning):源自bias问题。bias如果比较大,可能误伤某些离得确实很近的物体,导致阴影和物体断开。也可以叫阴影悬浮。工业界的处理一般就是找一个合理的bias。
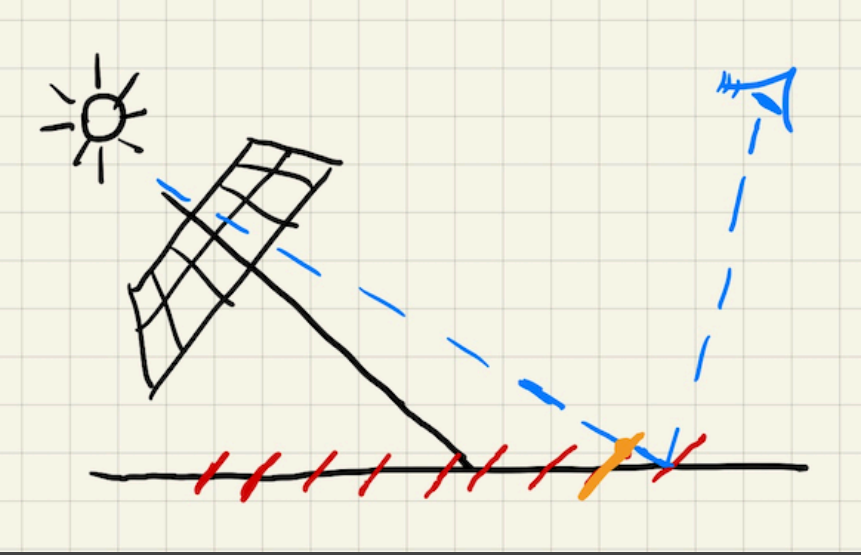

4. aliasing走样,源于shadow map的分辨率有限,因此会出现不可避免的锯齿边缘。
Q:什么是PCF(percentage closer filtering)?什么是PCSS(percentage closer soft shadow)?
从实践的角度来讲,PCF一般在fragment shader里面用到。此时已经有了shadow Map和采样点,但我们不是直接从这里取出一个非0即1的visibility,而是采样周围的很多点,然后平均这个visibility,得到一个0-1的中间值(假设在边缘附近)。
注意这既不是后处理(直接处理渲染完毕图像上的阴影边界),也不是改shadow Map(这个图代表深度,本身的物理意义使其不能被直接修改)。
这项技术最开始被用于实现AA(anti-aliasing 抗锯齿),但后续发现随着filter core的增加,阴影的边界变得越来越“软”,因此这项技术就成为了软阴影的实现方式。
接下来的一个关键问题是:filter core的大小选择。显然,core越大就越软。那么现实中的软阴影大小由什么决定呢:首先,是光源本身的大小,光源越大,造成的半影区面积显然也越大;其次,是blocker距离Receiver的距离(或者从下图来讲,是个相对距离),这个距离越大,半影区的面积也越大。
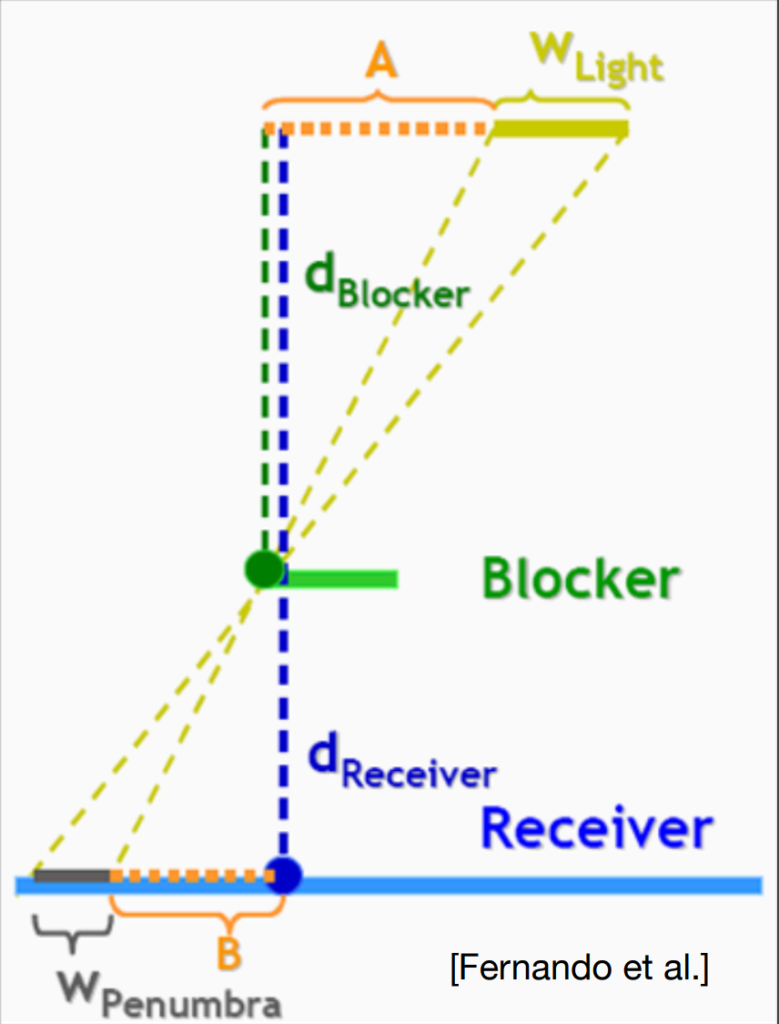
这就是PCSS,也就是PCF在软阴影问题上的应用算法:
The complete algorithm of PCSS
- Step 1: Blocker search
(getting the average blocker depth in a certain region) - Step 2: Penumbra estimation
(use the average blocker depth to determine filter size) - Step 3: Percentage Closer Filtering
问题:这个certain region本身又是什么呢?
他的物理意义是:在一个shadow Map的区域范围内,可能存在blocker遮挡从shading point到光源面的连线。这个范围取决于光源大小,receiver深度和light深度。
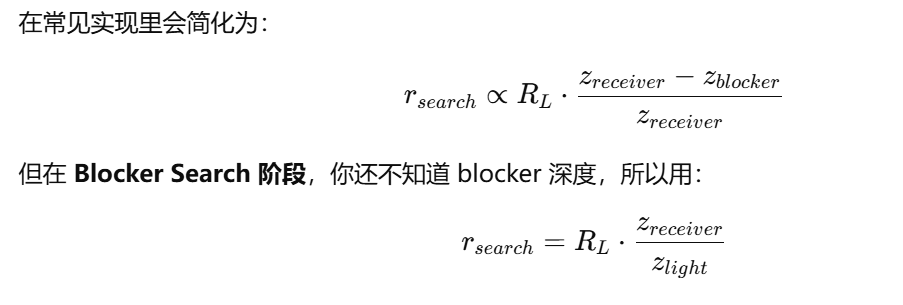
注意,大部分的深度存储(比如shadow Map)都是0-1,但这里存的默认不是线性深度,而是经过了projection压缩之后的非线性深度。在距离远平面越近的地方,精度就越差。在实战中需要注意这个问题。
Q:VSSM(variance shadow mapping)是什么?为什么出现?
在PCSS种,需要两次进行类似卷积的多重采样。step1中需要采样得到average blocker depth,step3中需要采样得到最终的visibility。显然这两步采样的消耗非常大。
一个常见的想法是,我们使用稀疏采样的方式,减少sample的数量。但这里就会导致另一些问题,比如单张图上的noise和连续渲染中,noise导致的fliker(抖动)问题。因此稀疏采样一般都配合图像降噪工作出现。这就是另一个大块的话题,denoisy去噪。
那么VSSM对这个问题提出了怎样的解决方式呢?
首先可以直观的想到,如果框选区域内的深度概率分布近似符合正态分布,由于第三步实际上在做的任务,类似寻找shading point深度在整体深度中的百分比,因此如果知道了这个区域内的深度概率分布的均值和方差,就可以对这里进行快速计算。
均值(mean):直观的想到可以利用hardware mipmap(快速,近似,范围查询)的形式来存储一个固定区域(这个由于硬件支持的原因,实际非常快),但由于mipmap只能是正方形,需要通过另外的数据结构summed area tables(类似一个二维前缀和矩阵)来做任意矩形。
方差(variance):方差 = 平方的期望 – 期望的平方,期望平方易得,而平方期望需要另外存一张类shadow map的图,里面存放的值是深度的平方。也就是空间换时间。如果深度本身不是特别高精度,可以写在一个float8里面(RGBA里的一个通道),那么平方可以只占用另外一个通道。
此时我们已经知道了mean和variance,此时考虑到计算正态分布的复杂性,VSSM抛弃了正态分布假设,提出了另外的一个近似,即通过切比雪夫不等式来近似(把不等当成约等来看)
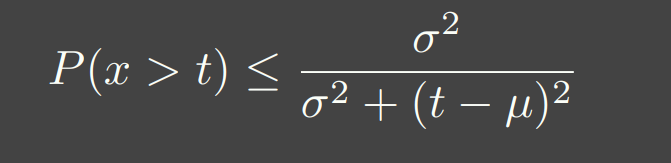
那么另一个问题:上面解决了step 3:PCF的近似,但step 1:blocker search(计算范围内平均遮挡物深度)仍没有解决,上面计算出来的均值是范围内所有深度平均,而不是遮挡物(z<t)深度平均。
我们假设这一块区域内的均值和方差是已知的(同step 3的解决方式一样)
对这个问题的解决方式涉及两个关键假设:
- 对x>t的比例,使用切比雪夫不等式估算出一个值
- 对于Zunocc(也就是非遮挡物的平均深度),直接使用t(一个hack,假设所有非遮挡物的深度都是shading point的深度,考虑到大部分阴影接受面都是平面,这样的近似也有一定的道理)。

可以看出VSSM是一个为了解决查询的速度无所不用其极的方法,做出了大量大胆的假设和近似,把原本大量的计算需求简化成平方和方差的查询计算。
但是,从业界的角度上看,由于降噪技术的进步,特别是空间和时间尺度上的方法(TAA),实际上目前更多仍然是使用稀疏采样的PCSS来做阴影。
Q:Moment shadow mapping是什么?为了解决什么问题?
VSSM的主要问题是:切比雪夫不等式的估计不是准确的。假设实际的结果和估计结果相差很大的话,就会出现阴影区overly dark或者overly lighting的问题。
常识:人们通常能接受一个阴影变得异常的“黑”,但不太能接受变的异常的“白”。这就是“Light leaking(漏光)”问题。
因此Moment shadow mapping就是为了解决“切比雪夫不等式对分布的描述不准”的问题。通过的方式是保留除了x和x平方之外的更高阶矩,从而能够更好的描述分布。当保留到四阶矩的时候,效果很接近PCF。
问题:由四阶矩重构原分布的计算过程,是非常复杂的,会导致perfomance问题。
Q:Distance field soft shadow是什么?好处?SDF(signed distance field)?
首先,distance function指的是:空间内任何一个点,到一个物体表面上的最小距离,记作这一点的distance function 的 value .
signed实际上是指,假设我们通过某种方式(比如规定物体的内部value为负值,外部value为正,就可以把unsigned变成signed,相当于使距离场有了“方向”, 也就是“有向距离场”)

一个例子:对于一个运动的物体边界,方便的进行线性插值得到中间的运动状态
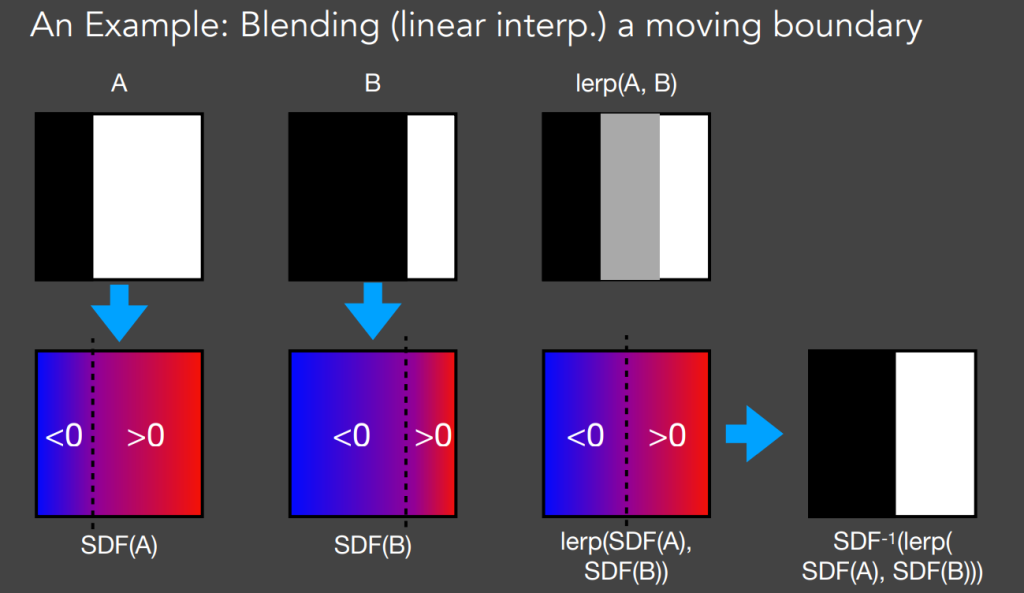
距离场的应用:
- Ray marching (sphere tracing) to perform ray-SDF intersection
- 光线追踪的主要任务是光与物体表面的求交。而SDF可以用来表示物体表面(区别于显式的物理表示)。
- 这里面的核心思想是:对于一个点,它对应的distance function表示,在这个距离范围以内,绝对不存在一个需要考虑的物体表面点,也就是所谓的“safe”。在ray tracing里面,这相当于一个跳步优化。
- 对于光线的起始点,查询到SDF值,然后就可以直接让光移动这么一大段距离,中间不需要做任何的查询。然后从下一个起点又可以重复这一个过程。这就是所谓的 ray marching(光线步进)。
- 一般到SDF比较小(准备查询),或者移动距离已经很远(准备丢弃),就终止。
2. Use SDF to determine the (approx.) percentage of occlusion
- the value of SDF -> a “safe” angle seen from the eye, 即不可能被遮挡,与visibility正相关
- 因此从shading point出发向着light进行类似ray marching的工作,然后找到一个近似的safe angle(一般是几个里面最小的),然后通过近似三角函数(指把arcsinx近似成kx)来得到 visibility。用k来控制软硬程度。
- pro:Fast(在光线追踪的体系下是很自然的),high quality
- cons:SDF的生成(precomputation),存储(heavy storage),不能处理形变,artifact(走样/穿帮)
SDF表示物体表面的问题:纹理/uv问题,由于缺乏原生UV坐标,导致上色,拉伸等问题。
Q:Environment lighting是做什么?实现方式?
环境光照的基本假设:光照无限远,不考虑遮挡。因此两个场景中位于不同位置的物体,实际接收相同的环境光照。
cubemap vs. sphere: 工业界一般用cubeMap,虽然占用大一点,但渲染简单,适合旋转,图像质量高
ps:对于render equation来说,由法线定义正半球,Li * brdf * cosθ仅对正半球积分。
Image-Based Lighting(IBL)
首先,IBL完全忽略阴影,因此visibility恒为1,渲染方程里面这一项忽略。
其次,对于BRDF项来说
- 如果brdf是glossy(高光/镜面):说明support(支持域,这里可以就理解为积分范围)很小,意味着它只接收来自极窄方向范围的光。
- 如果brdf是Diffuse(漫反射):表面非常光滑(Smooth),这说明它的brdf项在不同的光照方向上非常均匀,近似为常数。
如下的常用近似在什么情况下准确?g(x)的support比较小,或者比较smooth
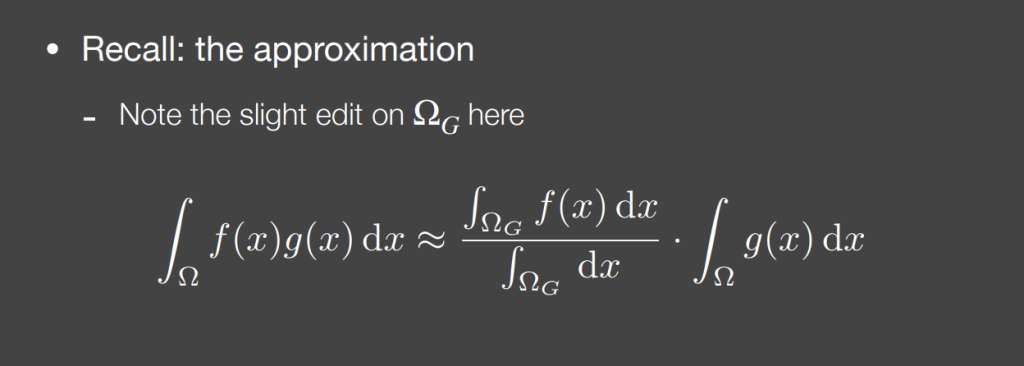
因此可以使用这样的拆分把渲染方程拆成两项:

这个Li项可以很容易的被解释成:在一个范围内Li的均值。因此这一项可以被预先计算,类似于mipmap的形式,预先存储一批mipmap,比如1级mipmap就可以查询2*2的filter结果,2级查询4*4,想查5*5只需要对2级和3级的对应结果进行三线性插值就可以了。这个查询的过程本身成本很低。
补充:有关BRDF lobe,roughness以及IBL Li项的工程实现
在物理材质模型(如 GGX 分布)中,Roughness 直接控制了高光波瓣的“宽度”:
- Roughness = 0:Lobe 变成一条线(完美镜面反射),积分范围是一个点。
- Roughness = 1:Lobe 变成一个极宽的“胖气球”,积分范围接近整个半球
因此,我们对应的积分范围实际上是由roughness决定的。
能直观的想到一种思路:我们预先把卷积核的大小和roughness的对应表存储好,然后在fragment shader里面,根据Mipmap和三线性插值进行查询。
但这里有一个问题:这里的mipmap虽然也是2层级,但是并不能简单的做2*2平均的下采样,而是应该对一个roughness值对应的BRDF lobe进行蒙特卡洛积分,然后使用自定义的 Compute Shader(计算着色器) 手动写入 Mipmap 的一层。
显而易见的问题:Roughness和Level层级的映射是什么?
ue4的实现中,使用了简单的线性映射 LOD = Roughness*(MaxMipLevel – 1)
但由于Roughness实际在用的时候是要平方(α = Roughness^2),因此物理上的模糊程度(α)随实际roughness的增加是2次的,也符合我们希望在光滑区更细致的初衷(人们对光滑的东西更敏感)。
为什么还要用mipmap:因为硬件层面线性插值的支持,在fragment shader里面调用线性插值的时候,用mipmap比手动更快。
Q:Level 1 分辨率变小了,能存得下复杂的卷积结果吗?
A:当Roughness增加时,反射本身就会变得非常模糊。模糊意味着高频细节消失,剩下的都是低频信号。所以,分辨率的下降(硬件特性)恰好匹配了模糊程度的增加(物理特性)。
补充:有关插值和mipmap
- 为什么要插值:因为uv是连续的,而texture是离散的。因此不是说采样点落到哪个像素就是什么颜色,而是根据这个采样点距离最近的四个像素中心对应的像素颜色,根据这个据中心距离进行双线性插值,得到采样颜色。
- 也就是说,纹理的本质是一个离散的点图,每个像素实际上只对应一个点(中心),其他位置都是插值出来的。
- mipmap的本质:是取四个像素的中心点进行线性插值,得到一个新的点。也就是说,它的本质是在加速一个“范围内均值”的查询。
- 三线性插值:在双线性插值的基础上,增加了mipmap层级作为一个新的维度,已适应非2倍数的范围查询。
对brdf的再理解:
Fresnel 项,决定了“反射率”,一个非常复杂的函数,通常用Schlick近似,也就是R0 + (1-R0)*(1-cosθ)^5。可以看出这个近似只和入射角度和R0(这个东西就是metallic)有关,也就是决定高光能量的占比。
NDF项,主要和微表面分布有关,h是一个查询的值。通常使用beckmann分布来描述(假设微表面的高度分布遵循高斯分布),核心参数是roughness(也就是α)。注意我们刚刚提到的近似,这里的roughness实际上就是物理上的roughness,等于实际我们参数中roughness的平方(也就是算式算了一个参数的4次方),当然这都是实现问题。
工业界中对于NDF更经常使用GGX分布。
G项:能量守恒,相当于小弟,主要影响微表面相互遮挡的情况
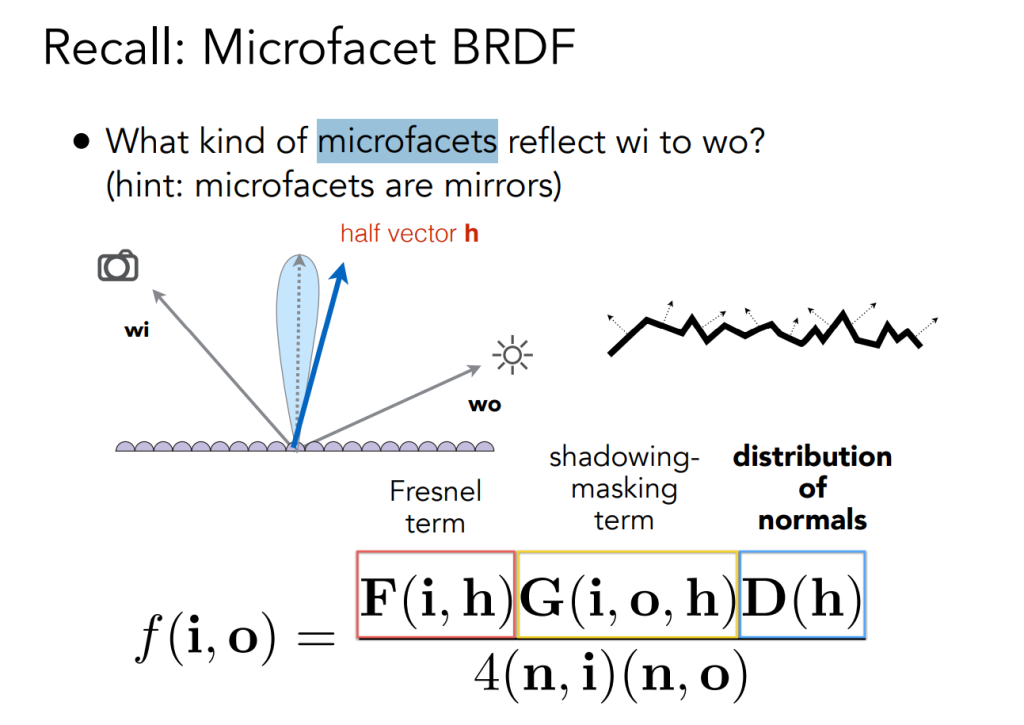

对于IBL的BRDF项,可以把Fresnel项显式的提出来,也就是完全把积分的结果转变为根据roughness和cosθ的函数。对于一个预计算来说,就是两张二维的表(如果我们考虑多通道,那实际上可能就是一个纹理的两个通道)

Split Sum:目前为止,我们需要的结构如下:
- Prefiltered Env Map (Cube Map):用于 Specular IBL(镜面反射)。实际上是一连串原图的mipmap,里面手动塞入了不同roughness(一般是线性映射,用的时候平方)对应brdf lobe卷积出的结果。
- BRDF LUT (2D Texture):用于修正 Specular IBL(解决菲涅尔和几何遮蔽积分)。一般是一个纹理的两个通道,R0(也可以是F0)项后面的一般叫Scale,另一项叫Bias
由于最后的结果在工程上是查表求和,因此这种方法叫做split-sum法
这种方法也是Unreal 4的PBR实现方案基础。
注意:这里更多是解决了镜面反射的效果。也就是让光滑平面低成本的反射周围环境。为了漫反射颜色,还需要球面谐波 SH。UE4用 3 阶球面谐波(Spherical Harmonics)来实现。
当然,怎样获得一个场景的environment Map又是另外一回事了。
Q:环境光照的shading有了,那么shadow怎么处理呢?
A:非常难
- 因为环境光照约等于“many-light”问题,因此成本线性于光照数。
- 从采样的角度上看,渲染方程中的vis项不可知,无法被提取出来(这里解释了AO为什么叫做“环境光遮蔽,因为它就是为了解决这里对于一个shading point来说,vis项无法提出的问题”)
- 当然,AO的大前提是 constant environment lighting,也就是环境光不能是任意的,需要在各个方向上都等于一个常量。显然,这是一个不太严谨的近似。
工业界一边都是取环境光照中最亮的光源(one or more)做代表(比如太阳)来产生阴影。
那此时为了完成这个环境光照下的阴影问题,自然的引入了PRT(Prefiltered Radiance Transfer)
Q:PRT是什么?做什么?好处?代价是什么?
首先需要知道一些基本的数学概念:
- Filtering和图片:对于图像来说,由于每个像素实际上是数值,因次衡量数值变化的剧烈程度也可以称之为频率。从这个角度,一张图片可以被转化为一张频谱。
- 此时Low-Filtering相当于把高频变化的部分滤除,也就是去掉了细节,保留了部分相对模糊的部分。
- 实际上卷积也可以达到类似的效果。直观的讲,卷积是在空间(Spatial Domain)上平滑了信号,在频域/时域(Frequency Domain)上看,相当于做了一个乘积(乘上卷积核对应的频谱)。
- 空域卷积=频域乘积
核心数学工具:SH球谐函数(Spherical Harmonics)
- 本质:一系列的二维基函数,变量定义为球面上的方向。
- 为什么球面上的方向是二维:θ + φ (没有 r/模 的三维向量)
- 因此,实际可视化的SH为空间中的一个物体(实际只有表面)
球谐函数有一个非常好的性质(这个性质源于球谐函数是一组标准正交基),即在求取某一项SH的系数的时候:
我们可以直观的理解为,系数就是f在某一个SH上的投影,因此简单的点积(当然是连续积分)就可以得到这一项系数。
理论上这个解析和恢复是无限阶的,但通常我们恢复只会用有限阶。
这里有一个非常有趣的点:实际上这个过程,就相当于我们把高频(对应高阶SH)对应的信息给滤除了。也就是天然的低通滤波,非常适合用于漫反射这种非常低频的信息。
对于不考虑Shadow的shading part:
Li是一个任意的球面函数,但如果只考虑diffuse BRDF项的话,这一项是非常smooth(低频)的,研究证明,可以用三阶的球谐函数来近乎完美的近似diffuse BRDF项 。
对于一个product integral来说,Li和diffuse BRDF实际上在求结果的时候只取决于低频。既然diffuse BRDF本身就非常低频,那其实也不用使用非常高阶的SH来描述Li项了。研究证明,使用三阶的球谐函数表述Li,误差仅在1%左右。
因此,我们可以只通过存一个vec9,来存储一个很”diffuse“,但够用的environment lighting,来计算漫反射环境光照。
在写到这里的时候,突然意识到一个一直以来的误解:BRDF一直是两项,diffuse项和specular项。cook-torrence模型和metallic/roughness属性都是属于specular项的,上面提到的split-sum技术也是为了解决specular项的问题。
但是其实diffuse项也是影响场景的关键因素,不能把这当成一个常量。
Q: PRT的思路:
Li * V * BRDF
假设BRDF是diffuse的:直接化成常数ρ提出来
Li可以化成SH的形式,把提出来的Bi(球谐函数分项)塞给V项,对于V来说约等于在某个方向上的投影,也就是一个数。这一项就可以预计算。
最后化成一个向量点积的形式。
代价:假设V不变,因此场景是不能动的。
好处:光照是可以切换的(只要都预计算出li系数项),而且由于SH函数优秀的旋转性质,可以比较容易的得到旋转光照之后的li系数项。
注意:由于这里是diffuse的,SH理论也可以3阶

另一种理解方式:直接把Li项和light transport项(也就是后面的一大堆,由于brdf diffuse, 可以只关注V)都拆开为球谐函数的形式。变成一个n平方的累积之后,由于SH交叉项为0,且对应项为1,因此此时退化为一个O(n)的点积,等价于上面的形式。

那么如果BRDF是glossy的,就会更复杂:
glossy物体的复杂性,体现在BRDF项不能被当作常数提取,它和观察方向(也就是出射光方向)是相关的。所谓高光/specular的语义也是这样,从不同的角度观察一个受同样入射光的物体,得到的结果不一样。
对于glossy的物体来说,Ti项就不能只是一个投影的向量(n维),而应该是投影的矩阵(n*n),存储来自不同方向上的light transport 在SH上的投影(SH系数)。
GI!(Global Illimination 全局光照)
在实时渲染中,我们需要解决的全局光照问题,实际上指的是“one bounce”问题,也就是所谓的”多一次弹射“作为间接光照的部分。
RSM(Reflective Shadow Map)
思考:实际上在对于一个shading point考虑光照的时候,它本身并不在意其接收到的来自某个方向的光,是直接来自光源的,还是来自其他物体反射的。也就是说:
全局光照,就是把所有受到光源直接照射的物体表面,当作新的光源处理(次级光源 secondary light source 相对于 primary light source)
需要处理的问题:
- 1. 哪些表面会被直接照亮(即作为次级光源)
- 2. 不同表面对shading point的贡献程度
对于问题1,我们的shadow map可以提供光源视角的图景,帮助解决“哪些是次级光源”的问题。但有一个关键的困难是,假设这个次级光源的radiance是出射方向有关的,那就非常麻烦了,因为在这里我们的观察角度不固定(shading point代替了camera的位置)。
所以这里做出了一个假设:所有的reflector 反射物都是diffuse的。即radiance视角无关。这样我们就可以把它当作一个简单的光源来处理。注意,此处并没有假设接受物(也就是shading point)也是diffuse的。
核心推导如下:q代表reflector p代表shading point。在这个问题里面,把次级光源的光照直接表述为brdf * 能量/面积的形式,这样就能在shading point计算的时候把单位面积消掉,达成只存取能量的优化。
由于这个公式的V项一眼难算,因此RSM是不考虑V项的

当然,对于任意的shading point考虑每一个shadow map上的点的贡献,在大多数情况下仍然是不可接受的。因此就需要做一些聪明的采样策略,找到哪些点可能对shading point有贡献。
在RSM里面,是把shading point的世界坐标投影到shadow map上,然后假设这个shadow map上离得近就是世界坐标近。这里有点像是PCSS对于shadow map找blocker和filtering的那个过程。然后开始调参!
通过这种做法,把对于单个shading point的次级光源数减少到了400个左右。
这里的Shadow map存储了Depth, world coordinate, normal, flux, etc这些信息
一般在游戏中,解决手电筒相关的间接光照会用RSM(可能因为电筒本身只照亮一小块区域,因此相当于间接光源的数量也有限制)。
Pros:非常好写,遵循shadow map的流程
Cons:
- 有一个直接光源,就要多一张shadow map
- 反射物到shading point的V做不了,真实感问题
- diffuse 反射物, 世界坐标与shadow map的距离近似
- sample rate/quality tradeoff
Light Propagation Volumes(LPV)
核心思路:把3d空间体素化为一个网格结构,然后对于每一个次级光源(注意这里需要先通过类似RSM的方式,得到所有的次级光源以及其对应的Radiance分布),通过“扩散”的方式传播光源
要避免一个思维误区:光是沿直线传播的。实际上在这里的光,被表示为一种辐射场的形式,也就是说,简单的通过一个向量点乘固定方向,就可以得到某一个方向的辐射分量。可以很简单的想到,不同方向上的分量重新加起来就是原始起点的场。
也因此,传播的过程和“光源起点”和“光线”没什么关系,主要是场在进行流动。在这里场表示为2阶SH。
问题:
- 1. 如果有小于一个格子的面片,会有light leaking
- 2. 无限制的细分网格,存储和扩散计算都有压力
VXGI(Voxel Global Illumination)
实现思路:依然把场景voxel化,然后对于每个小格子,记录其接受到的incident lighting lobe和其normal lobe,这样就可以计算对任何一个shading point来说,这个次级光源的光照贡献。
另一个重要思路是:对于每一个shading point来说,从camera出发发射一个camera ray,打到shading point表面反射。如果是glossy,则反射出一个圆锥;diffuse则反射出一个半球,这里解决为多个圆锥的拼合。理论上来说,考虑这个圆锥覆盖的,所有小格的光照贡献,就能够计算间接光照。
为了加速这个过程,在初始化的时候,会为场景的网格设置hierarchy。考虑到圆锥是上窄下宽的,因此初始的时候找最小层级的voxel,越往后可以越找高层级的voxel,类似RT的包围盒?
Pros:效果非常好,因为是逐像素处理的技术
Cons:慢,以及voxel化成本
GI in Screen Space
所谓”屏幕空间方法“,都是基于已经渲染出的图像结果的“post processing”!得到的信息仅仅是在camera的可见范围。可以想到,这些方法对GI的处理,必然是高度近似的。对立的概念是“image space”,也就是像RSM这种,从shadow map中获取信息的方法,和“world space”,LPV/VXGI
SSAO(Screen Space Ambient Occlusion)
Q:AO为了达到什么样的画面效果?为什么谈GI会突然转到AO?
A:AO是让物体和物体之间的接触部分变暗的技术(所谓的 contact shadow),是为了体现物体的相对关系,避免悬浮感,体现立体感。因为AO是很容易实现的技术,它可以被视为GI的一个近似(contact shadow本身就是全局光照造成的一种现象)
SSAO 的 key idea:
1. 在我们不知道对于一个shading point来说,它接收到的来自四周的间接光照的具体的值的情况下,其大胆的假设,所有方向的值为一个相等的常数(调参地狱?)
知识点回顾:在Blinn-phone 光照模型中,同样做出了这样的假设。最终导致结果项中出现了一个环境光照diffuse固定项,直接强硬的把场景提升一个固定的亮度。
2. 但SSAO毕竟是AO,它虽然假设常数,但考虑visibility,也就是,不是所有方向的这个常数,最终都产生了实际的光照效果(要乘上visibility)
3. SSAO还假设,所有物体的材质都是diffuse的。
如下面的公式推导,可以得到:对任何一个shading point,其能得到的间接光照的值,等于一个visibility对于半球的加权平均值,乘上一个精心调制的常数(光照常数 * diffuse brdf 常数)

为什么这里面带着cosθ一起积分?因为这两项的乘积有明确的意义:dω本身代表立体角,也就是单位球上的面积。它乘上cosθ实际上就是投影到单位圆上的面积(所以上面ka的分母是Π:圆面积)
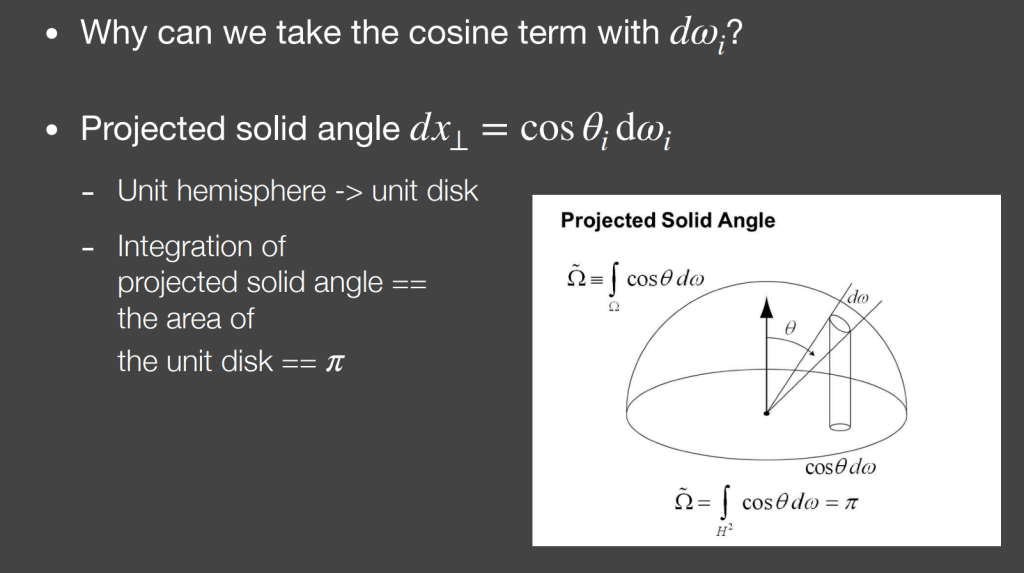
Q:怎么去实时计算ka(也就是 visibility项的加权平均)?特别是在screen space?
首先:在这里计算visibility的时候,不能假设光是来自无限远距离(因为反射光肯定不是无限远)。因此在 visibility 去 trace 的过程中,肯定也是需要一个固定的距离,超过这个距离的就不予考虑(想象一个封闭的屋子,如果无限远,则visibility肯定为0).
这就产生了trade-off:到底这个“有效距离”是多少,要根据实际情况而定。
更重要的问题是,在screen space不好做ray tracing 对此 SSAO做出了一个大胆的假设:
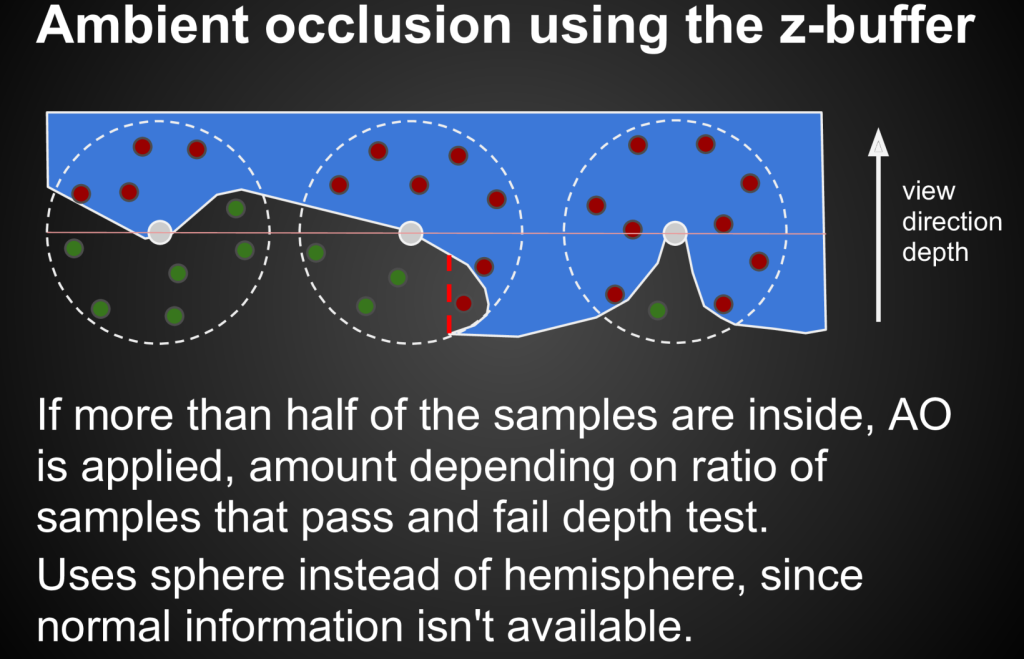
首先:对于一个shading point,向它周围的一个整球的范围内采样一批点。对于这些采样的点,可以根据深度图中的深度信息(会标记相机方向的最小深度),判断它是在物体内部还是在物体外部。当然,在图二这种情况下可能会出现误判,但整体不是很影响。(课上有一个石凳的例子说明了这种情况有时候会产生不自然的AO, 解决这个问题的方式叫HBAO,会考虑法线信息和深度衰减,而不是挡住都算)
其次考虑到只有法线方向上的那个半球的信息才实际对ao有效,而由于历史原因,SSAO那个时候还不能同时存储深度和法线,因此做了这样的判断:只有红点的个数过半,才考虑AO。红点不过半,visibility项显然是全1;红点过半,那把减去整体个数一半的红点个数再和绿点去比较,得到visibility项。图2是0.6,图三是0.2。
当然,这种做法只是平均,而不是和cosθ合在一起的加权平均。但工业界不太影响。
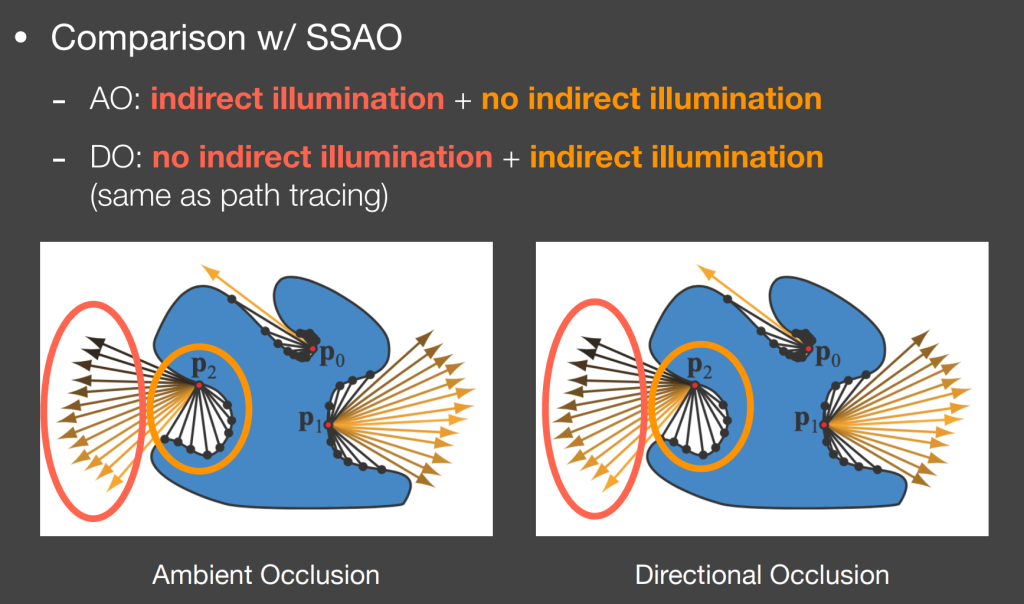
SSDO(Screen Space Directional Occlusion)
SSAO假设 incident light 为 constant,但这种做法实际上只能让接缝处变暗,并不能做到color bleeding的效果(两个diffuse的物体把自身的颜色互相传播)。
SSDO的思路类似path tracing:从shading point 发射出很多条光线,如果打到了obstacle,说明有来自这个方向上的反射光线;如果打不到,说明只有直接光照。
从这个角度上看,由于SSAO的constant假设,其实际上是用考虑直接光照的思路来考虑间接光照,假设间接光照都来自于环境光(较远的地方)。与SSDO正好相反,打不到说明有间接光照,打到了说明被遮挡住。而SSDO则考虑近处的反射。理论上,应该两个一块做(但好像没有应用实例)。
Pros:质量还不错,速度可以接受
Cons:
- screen space丢失信息,camera看不到的面,根本就不知道存在,因此也就不贡献shading
- 只能考虑一个小范围内的间接光照(由于其也使用类似SSAO的,拿半球内采点当作ray tracing的近似,因此其不能处理稍大范围内的反射光/间接光照)。
SSR( Screen Space Reflection / Ray tracing)
- Raymarching: SSR shoots a ray from the camera, reflecting it off a surface, and then “marches” (traces) this ray across the screen’s depth buffer to find an intersection with another object.
- Data Usage: It relies on the depth, normal, specular, and color buffers to compute the reflection.
- Sampling: When a hit is detected, the color from that part of the screen is applied to the reflective surface
Hierarchical tracing:类似mipmap的计算方式,不过计算的不再是平均值,而是深度最浅值。可以很容易的想到,当ray不与high level的深度块相交的时候,它同时也不可能与这个high level下对应的low level相交。通过这种方式,可以跳过大量的计算块。
实际的计算中,采取一种“试探”的形式来完成这个求交的过程。大体上是:从最小的level开始步进,假设是一个像素块,然后步进2,4,8,直到相交。然后对于相交的那一块,通过逐级二分缩减的方式,最终找到对应的那个最低level的块。
SSR的问题同样也是screen space的问题:没有屏幕空间之外的信息,会导致反射细节的缺失。比如,实际反射计算只考虑深度图对应的那一层壳,因此就会有大量的没有被看到(但理论上应该被反射)的部分细节缺失。
PBR and PBR Materials
microfacet models and Disney principled BRDFs(both not PBR)
Microfacet BRDF
简单复习传统BRDF:
Fresnel:反射率,非金属的物体垂直基本为0,接近掠射时为1。特别metallic的物体垂直的时候就很高。大概反映了在某个角度下,材质反射能量的能力(可以认为0是完全不反射,1是完全不损耗)
一般使用Schlick近似一个从R0到1的一个变化轨迹(metal的R0接近1,非金属的接近0)
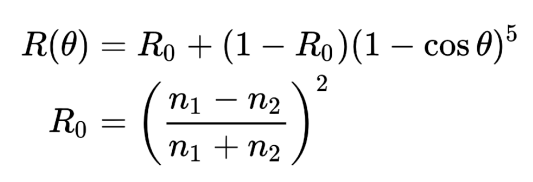
NDF(Normal Distribution Function)项:微表面法线分布,表示一种趋势。直观上,可以理解为材质是否smooth(法线是否集中)。理论上,如果平面是理想的,那么其法线的方向应该全部朝向半程向量h。
NDF项最终决定了物体是glossy(最极端的就是specular )的还是diffuse的。
NDF项的近似:Beckmann,GGX