一. 安装
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-2-local_12.2.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-2-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
Q:The libtinfo5 package isn’t available
A: Open a terminal window and run:
sudo nano /etc/apt/sources.list
Add this line:
deb http://old-releases.ubuntu.com/ubuntu/ lunar universe
Save and exit, then run:
sudo apt update
…and now the install command for CUDA should work, automatically downloading and installing libtinfo5 while installing CUDA.
Q: how to change env variable?
A:
cd ~
nano .bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.2/lib64
export PATH=$PATH:/usr/local/cuda-12.2/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-12.2
export PATH=/usr/local/cuda/bin:$PATH
source ~/.bashrc
Q:编译的时候出现错误,提示gcc问题
A:我使用的cuda12.2不支持较新的gcc版本,可以支持gcc-11。安装后,在编译时通过指示编译器版本来编译。
e.g.
nvcc -ccbin gcc-11 test.cu -o test二. 理论知识
1. 查询
nvidia-smi 查询基本信息
nvidia-smi -q 查询详细信息
nvidia-smi -q -i 0 查询第一块GPU的信息
nvidia-smi -q -i 0 -d MEMORY 查询第一块GPU的特定信息
nvidia-smi -h 查询指令使用方式
2.认识核函数
2.1 一维线程模型(grid-block-thread)
为什么要有block->加一个中间层,方便统一组织一些任务
下面以一维模型为例子
gridDim.x grid的维度(有几个线程块)
blockDim.x block维度(有几个线程)
blockIdx.x block序号
threadIdx.x 每个block中thread的序号
Idx = threadIdx.x + blockIdx.x * blockDim.x (很好理解,从块0的第0线程到做i后一个块的最后一个线程顺序编号)
2.2 高维线程模型
cuda最多支持组织三个维度的grid和block,显然,可以通过调用xyz来获得三个维度的信息
当拓展到多维的时候,再观察之前的类似 helloFromGPU<<<4, 4>>>(); 的形式,可以发现实际上每个位置上应该是一个uint3,这里再执行过程中是将没有指定的其他所有信息默认为1,即砍掉了该维度
bid: grid中第几个block
tid: block中第几个thread
注意!和多维数组编码不一样的一点:在索引计算的时候,是按照x,y,z的顺序变化的,而不是z,y,x
也就是说,(0,0,0)的下一个是(1,0,0)而不是(0,0,1)。这一点要习惯一下。
按照层,行,列的说法来说,应该是z层,y行,x列,x最多变。
gridDim的限制:x,y,z分别是2^32-1, 2^16-1,2^16-1
blockDim有两个限制:1. x,y,z分别是1024, 1024, 64 2. 总的blockDim(也就是乘积)不大于1024
3. nvcc编译
3.1 编译流程:.cu -> .ptx -> .cubin -> .exe
Q:为什么要有ptx文件?
PTX(Parallel Thread eXecution)是 CUDA 的”中间汇编语言”,相当于 CPU 世界的”字节码(bytecode)”或”中间表示(IR)”。
核心作用:硬件兼容性
为什么需要 PTX:
- “一次编译,多处运行”
// 你的 .cu 源码 → 编译为 PTX → 在不同架构的 GPU 上运行
// PTX 可以在 RTX 3060、4090、A100 等不同 GPU 上执行- 解耦编译时和运行时
- 编译时:生成与具体硬件无关的 PTX
- 运行时:GPU 驱动将 PTX 实时编译为对应硬件的机器码
- 支持未来硬件
- 今天编译的 PTX 代码,明天的新 GPU 也能运行
- NVIDIA 无需为每个新架构重新发布编译器
编译流程对比:
传统 CPU 编译:
源码(.c) → 汇编(.s) → 机器码(.exe) → 直接在 CPU 运行
CUDA 编译:
源码(.cu) → PTX(.ptx) → 运行时编译 → CUBIN → 在 GPU 运行
↑
(由 GPU 驱动完成)实际例子:
# 生成 PTX 文件(可跨代 GPU 使用)
nvcc -ptx mycode.cu -o mycode.ptx
# 生成特定 GPU 的 CUBIN(性能最优)
nvcc -cubin mycode.cu -o mycode.cubin总结:PTX 是 NVIDIA 解决”不同代 GPU 架构差异”的智能中间层,平衡了兼容性和性能。
3.2 指定虚拟架构计算能力
- C/C++源码编译为PTX的时候,可以指定虚拟架构的计算能力,用来确定代码中可以使用的CUDA功能
- C/C++源码编译为PTX,这一步骤和GPU硬件无关,可以看作声明(告诉设备,这个文件超出你的能力范围了,不能执行)
- 编译指令: 编译出的可执行文件helloworld只能再计算能力大于等于6.1的GPU上跑
nvcc helloworld.cu -o helloworld -arch=compute_61- 补充有关计算能力:代表架构的定义,不代表实际性能。实际性能多用TFLOPS(浮点数运算峰值来定义)。前面为主版本,后面为次版本。主版本号不同的GPU一般差异很大,机器码也大概率不能共用,次版本则一般只有细微差异
- 实际上这里也体现出PTX的价值,针对不同架构的GPU,为了确保代码的兼容性,需要这样的中间层
- 一般情况下,为了更兼容,虚拟架构的指定会尽可能低
3.3 指定真实架构计算能力
- PTX编译为cubin的时候,可以指定真实架构的计算能力。这与具体的GPU架构有关。
- 大版本之间不兼容!!!因为涉及到二进制的cubin代码
- 指定真实架构计算能力时,必须指定虚拟架构计算能力
- 指定的真实架构计算能力必须大于虚拟架构计算能力(很好理解,虚拟架构指定声明了最低版本,真实的肯定要大于它才能跑)
- 小版本的兼容性:比如指定为6.0,那么实际跑在6.1还可以工作。但是指定为6.1,实际跑在6.0上就不能工作(通俗的理解:越大就越强,指定较弱的代码可以跑在强机器上,但仅限小版本)
- 补充一点:NVIDIA GeForce RTX 3060 = sm_86
nvcc helloworld.cu -o helloworld -arch=compute_61 -code=sm_623.4 指定多个GPU版本编译
- 使编译出来的可执行文件可以在多GPU中执行
- 同时指定多组计算能力(不同的指定中间以空格隔开)
-gencode arch=compute_50,code=sm_50
-gencode arch=compute_60,code=sm_60- 在指定时,需要考虑cuda版本支持,比如cuda12.2就不再支持计算能力3.5的GPU了
3.5 cuda在没有指定的时候,会有一个默认计算能力,目前10.0到12.4之间的默认编译目标都是sm_52
- sm是什么:Streaming Multiprocessor
三. 代码框架demo
1. 程序框架
include <头文件>
核函数部分
int main(void)
- 设置GPU设备
- 分配主机与设备内存
- 初始化主机中的数据
- 数据从主机复制到设备
- 调用核函数在设备中进行计算
- 将计算得到的数据从设备传给主机
- 释放主机与设备的内存
e.g.
#include <stdio.h>
#include <cuda_runtime.h>
// ===================== 核函数部分 =====================
__global__ void myKernel(float *d_out, const float *d_in, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x; // 全局线程索引
if (idx < N) {
d_out[idx] = d_in[idx] * 2.0f; // 示例:每个元素乘 2
}
}
// ===================== 主函数 =====================
int main(void) {
// 1. 设置 GPU 设备(可选,多 GPU 时指定)
int deviceId = 0;
cudaSetDevice(deviceId);
// 2. 定义问题规模
int N = 1 << 16; // 65536 个元素
size_t size = N * sizeof(float);
// 3. 分配主机内存
float *h_in = (float*)malloc(size);
float *h_out = (float*)malloc(size);
// 4. 初始化主机数据
for (int i = 0; i < N; i++) {
h_in[i] = static_cast<float>(i);
}
// 5. 分配设备内存
float *d_in, *d_out;
cudaMalloc((void**)&d_in, size);
cudaMalloc((void**)&d_out, size);
// 6. 将数据从主机复制到设备
cudaMemcpy(d_in, h_in, size, cudaMemcpyHostToDevice);
// 7. 配置线程块与网格
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// 8. 调用核函数(在 GPU 上并行执行)
myKernel<<<blocksPerGrid, threadsPerBlock>>>(d_out, d_in, N);
// 9. 同步等待 GPU 完成计算
cudaDeviceSynchronize();
// 10. 将计算结果从设备复制回主机
cudaMemcpy(h_out, d_out, size, cudaMemcpyDeviceToHost);
// 11. 检查部分结果
for (int i = 0; i < 10; i++) {
printf("h_out[%d] = %f\n", i, h_out[i]);
}
// 12. 释放设备与主机内存
cudaFree(d_in);
cudaFree(d_out);
free(h_in);
free(h_out);
// 13. 重置设备(释放上下文)
cudaDeviceReset();
return 0;
}
2. 设置GPU设备的常用函数
- 一个小常识:很多cuda的函数会返回cudaError_t类型,用来做错误检查。需要取数据往往用引用
// 返回GPU设备数量
int iDeviceCount = 0;
cudaGetDeviceCount(&iDeviceCount);
// 设置GPU执行时使用的设备(只有一个,因此用0)
int iDev = 0;
cudaSetDevice(iDev);
3. 内存管理
内存分配(cudaMalloc),数据传递(cudaMemcpy),内存初始化(cudaMemset),内存释放(cudaFree)
3.1 内存分配
float *fpDevice_A;
cudaMalloc((float**)&fpDevice_A,nBytes);3.2 数据拷贝
// 四种拷贝:
// cudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice
// 注意这里的第一个参数是dst,第二个参数是src,所以什么to什么的顺序实际上是相反的
// 如HostToDevice, 那么第一个参数是Device地址,第二个参数是Host地址
cudaMemcpy(Device_A, Host_A, nBytes, cudaMemcpyHostToHost)
3.3 内存初始化
// 按照字节数进行初始化,初始化为0防止数据访问时出现错误
cudaMemset(fpDevice_A,0,nBytes);
3.4 内存释放
cudaFree(pDevice_A);
4. 自定义设备函数/核函数/主机函数
4.1 自定义设备函数
- 定义:只能执行在GPU设备上的函数为设备函数
- 设备函数只能被核函数或其他设备函数调用
- 设备函数用__device__修饰
4.2 核函数
- __global__修饰,主机中调用,设备中执行
- __global__修饰符不能与其他两个混用
4.3 主机函数
- 主机端普通c++函数可以用__host__修饰,也可以省略
- 可以同时用host和device修饰一个函数来减少冗余代码(因为这两个函数一般都不涉及设备与主机的交互,通常都是在各自的本地上进行),编译器会针对主机和设备分别编译该函数
5. 错误检查
5.1 cudaError_t
- cudaError_t是大部分cuda runtime API 的返回值类型,这个返回的执行状态值是一个枚举变量
- cudaSuccess = 0
- cudaErrorInvalidValue = 1
- cudaErrorMemoryAllocation = 2
- cudaErrorInitializationError = 3
- cudaErrorCudartUnloading = 4
- …
5.2 错误检查函数
// 获取错误代码对应名称
cudaGetErrorName(cudaError_t error_code);
// 获取错误代码描述信息
cudaGetErrorString(cudaError_t error_code);
// CUDA error checking
// filename: use __FILE__
// lineNumber: use __LINE__
cudaError_t ErrorCheck(cudaError_t error_code, const char* filename, const int lineNumber){
if (error_code != cudaSuccess)
{
printf("CUDA error:\r\ncode=%d, name=%s, description=%s\r\nfile=%s, line=%d\r\n",
error_code, cudaGetErrorName(error_code), cudaGetErrorString(error_code), filename, lineNumber);
}
return error_code;
}5.3 检查核函数的错误
Q: 为什么核函数是特殊的?
A: 所有的核函数的返回值默认为void,不反悔cudaError_t,因此不能用以上的方法进行检查
ErrorCheck(cudaGetLastError(),__FILE__,__LINE__);
ErrorCheck(cudaDeviceSynchronize(),__FILE__,__LINE__);6. cuda计时:性能检测
6.1 事务系统计时
cudaEvent_t start,stop;
ErrorCheck(cudaEventCreate(&start), __FILE__, __LINE__);
ErrorCheck(cudaEventCreate(&stop), __FILE__, __LINE__);
ErrorCheck(cudaEventRecord(start), __FILE__, __LINE__);
cudaEventQuery(start); // 此处不可用错误检测函数
/**************************************************************
需要计时的代码
**************************************************************/
ErrorCheck(cudaEventRecord(stop), __FILE__, __LINE__);
ErrorCheck(cudaEventSynchronize(stop), __FILE__, __LINE__);
float elapsed_time;
ErrorCheck(cudaEventElapsedTime(&elapsed_time, start, stop), __FILE__, __LINE__);
printf("Time = %g ms.\n", elapsed_time);
ErrorCheck(cudaEventDestroy(start), __FILE__, __LINE__);
ErrorCheck(cudaEventDestroy(stop), __FILE__, __LINE__);6.2 nvsight
- 快速看性能瓶颈
nsys profile ./a+nsys stats ./report1.nsys-rep - 详细核函数性能
ncu ./a.out - 完整指标采集
ncu --set full ./a.out - 只关注一个 kernel
ncu --kernel-name regex:myKernel ./a.out
四. 组织线程模型(光线追踪器?)
1. 二维网格二维线程块
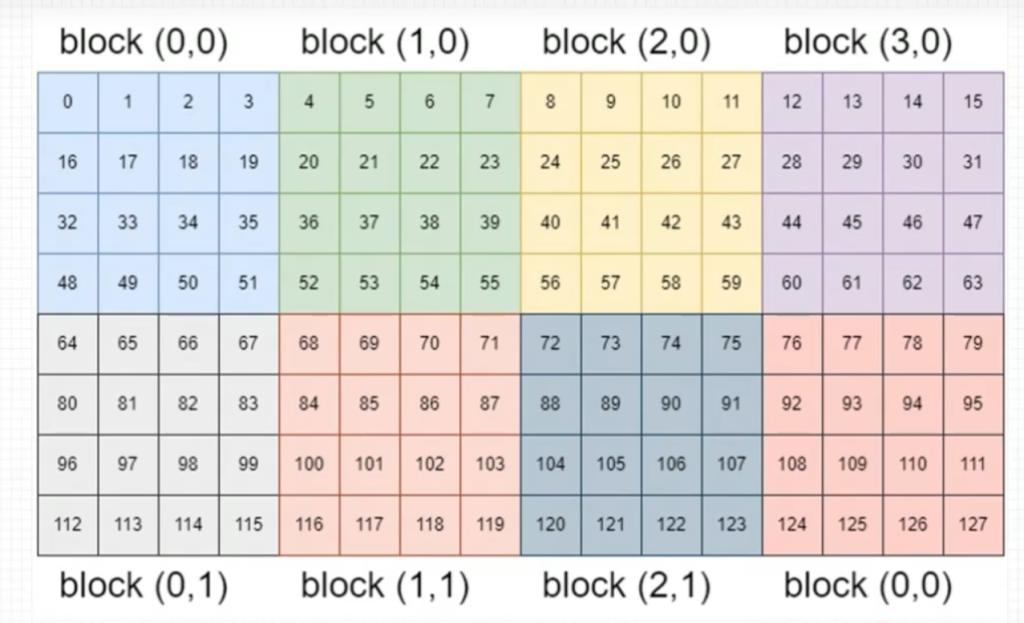
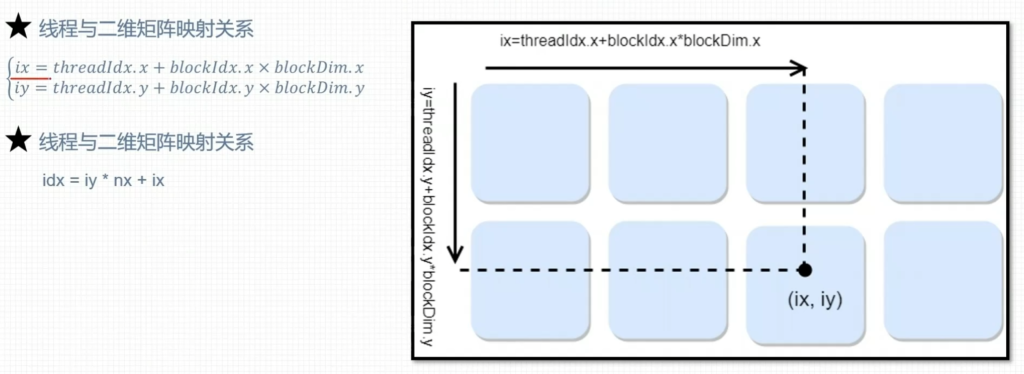
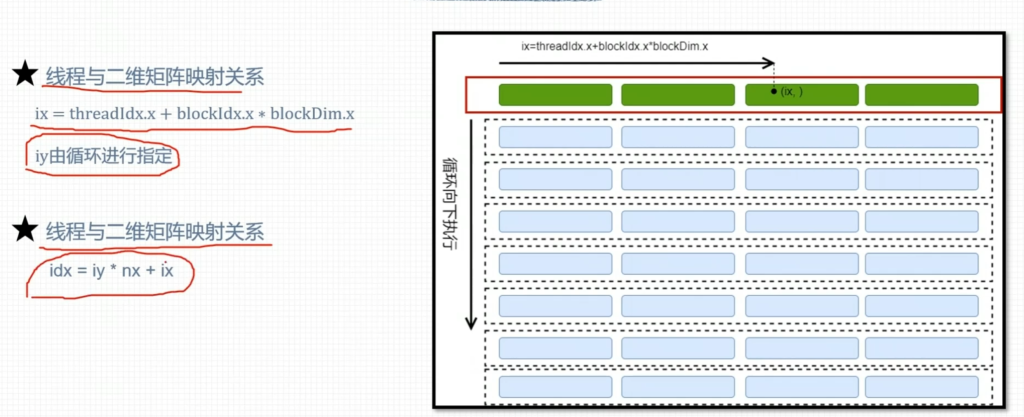
2. 二维网格一维线程块
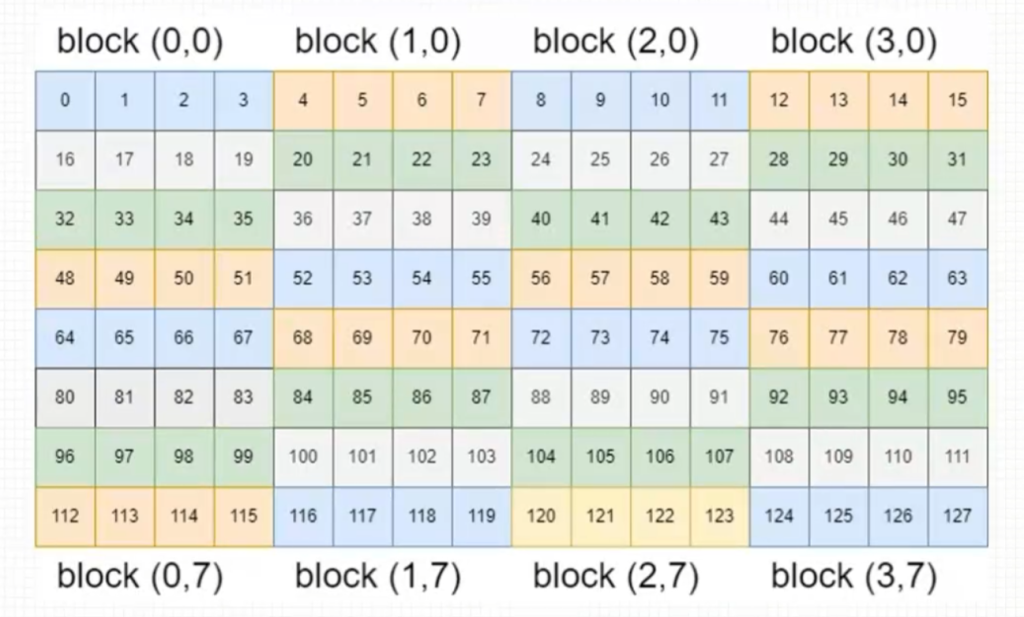
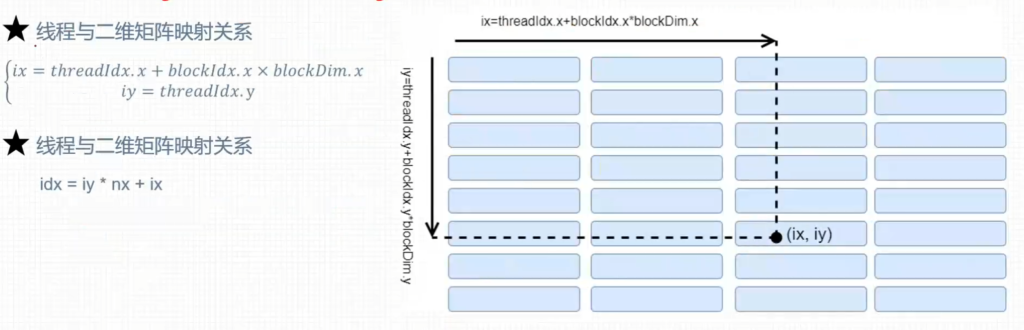
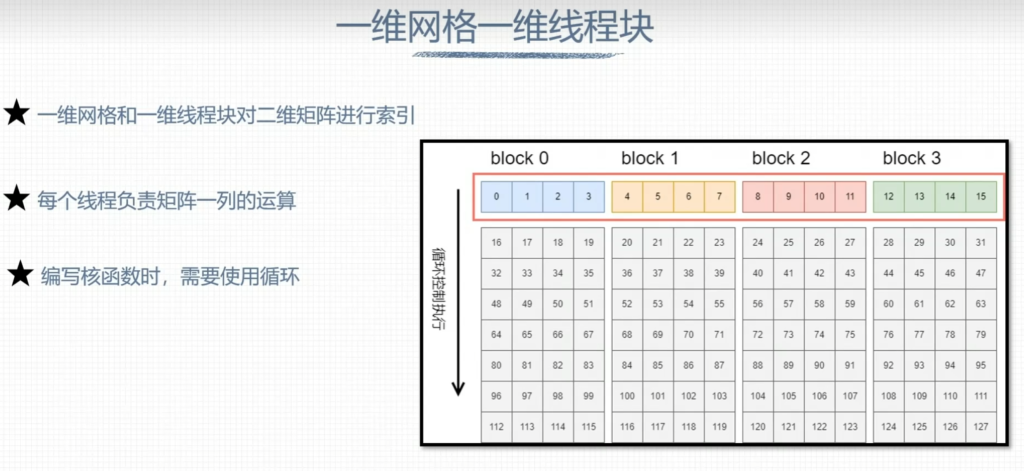
3. 一维网格一维线程块
五. GPU硬件资源
1. SM-Streaming Multiprocessor
- SIMT 单指令多线程架构
- 一个线程束含有32个线程。在一个线程块中,0-31属于第0个线程束,依次类推
- 每个线程束中只能包含同一线程块中的线程
- 重点:线程束是GPU硬件上真正做到了并行,在这之上的结构本质上都是在做并发
- 为了最大化效率,需要使线程块中的线程数量是32的整数倍
- 线程块中的所有线程必须全部被分配到一个SM上,但一个SM可以被分配多个线程块
- 一个线程块不能被分配到很多SM上
- 在一个SM上,支持很多线程并发执行。
- 并发与并行的区别:并行指互不干扰的平行执行。并发指通过调度的方式,好像在并行执行,但实际在每个时刻只执行一个任务。
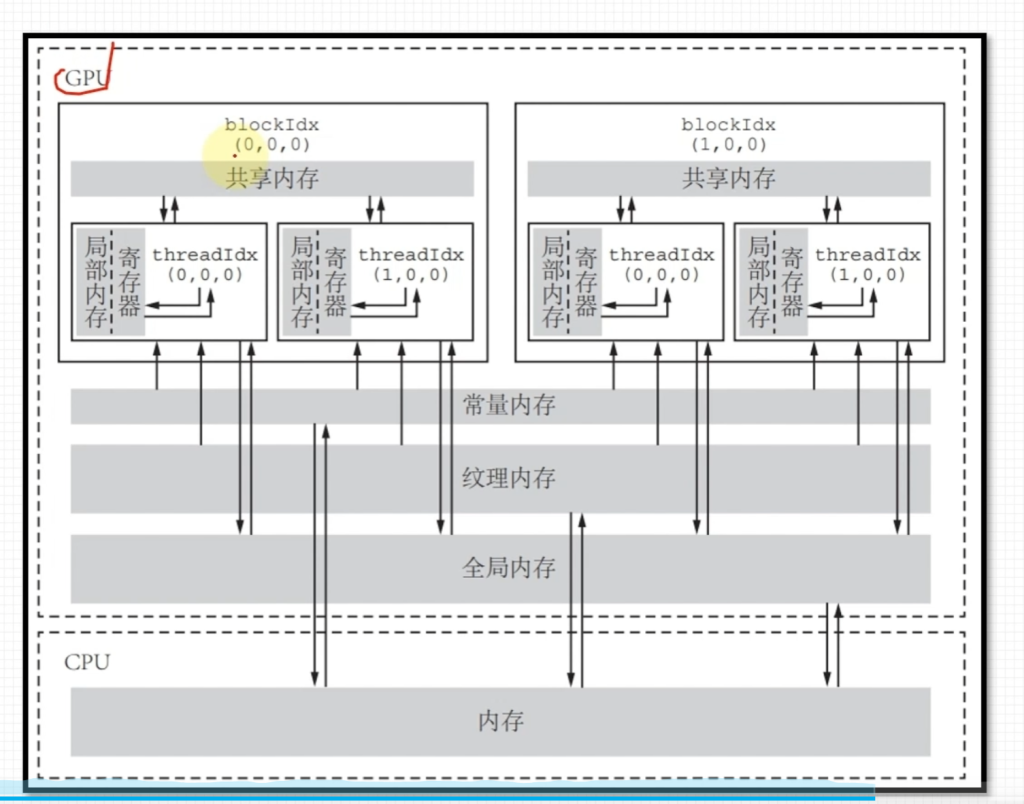
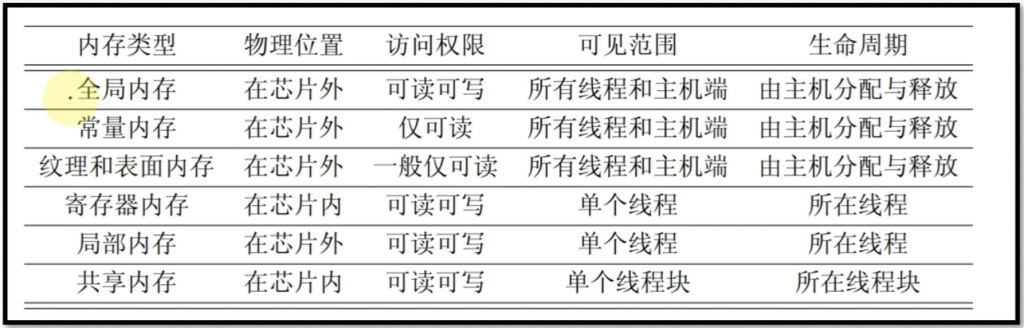
2. 内存模型
- 寄存器-缓存-主存(运行内存)-磁盘存储器
- 主存-DRAM(动态随机存储器) 低延迟内存-SRAM(静态随机存储器)
GPU内存架构
- 寄存器(register) – 属于线程的概念,不能共享
- 共享内存(shared memory) – 属于线程块的概念,一个线程块中的线程可以共享这部分内存。由于共享内存是片上内存,距离处理器比较近,延迟低,带宽大,具有高速访存的特性,因此需要高速访存的数据可以保存在共享内存中。
- 本地/局部内存(local memory) – 属于线程的概念,不能共享,相对于寄存器较慢,相对于共享内存也较慢,因为它不是(芯)片上的内存
- 常量内存(constant memory) – 属于全局的概念,只能被读不能被线程写(可以被CPU写)
- 纹理内存(texture memory) – 属于全局的概念,只能被读不能被线程写(可以被CPU写)
- 全局内存(global memory) – 属于全局的概念,是GPU中最大的内存,可读写
2.1 register, local memory
- 核函数中定义的,不加任何限定符的变量一般存放在寄存器中(如__shared__保存在shared memory中)
- 内建变量存放在寄存器中,gridDim,blockDim,blockIdx
- 核函数中定义的,不加任何限定符的数组可能在register,也可能是local
- 寄存器是32位的,相当于一个double需要两个寄存器
- 对于我的sm_86,每个SM中含有64K个寄存器,一个块最多同时使用64K(也就是全用),对于每个线程来说,最大的寄存器数量是255个

- 寄存器放不下,就会放在local memory
- 对于一个线程,可以使用512KB的本地内存,而对应的寄存器内存就要小的多,最多只有(255/2)B
- 从硬件角度看,local是global的一部分,属于片外内存,延迟很高,因此要尽量避免使用。因此,在程序设计时要尽量避免溢出,多用寄存器
- 对于计算能力2.0以上的设备,local存储在每个SM的一级缓存和设备的二级缓存中
- 寄存器溢出:一个SM并发运行大量的线程块/线程束,总的需求容量大于64KB,或者单个线程运行所需的寄存器数量大于255个,就会发生寄存器溢出。这会降低程序的运行性能
- 这个溢出的部分也可以保存在缓存中,从而提高效率
- 检查寄存器命令 nvcc –resource-usage hello.cu -o hello -arch=sm_86
2.2 global 全局内存,静态初始化与动态初始化
- 特点:容量最大,延迟最多,使用最多
- 数据所有线程可见,host端可见,且具有与程序相同的生命周期(即由主机端进行决定)
全局内存初始化:
- 动态全局内存:host端使用runtime API cudaMalloc动态声明内存空间,由cudaFree释放
- 静态全局内存:使用__device__关键字静态声明全局内存,在编译器编译的时候就确定下来。
- 一个需要注意的点:静态全局变量必须要在所有的主机函数和核函数之外声明,这样才能体现它的全局性。核函数可以直接访问静态变量,不需要变量的传递过程。但是!主机中的函数是不能直接访问静态全局变量的。需要通过以下两个API进行读写:
cudaMemcpyToSymbol(const void *symbol. const *src, size_t count, size_t offset, cudaMemcpyKind kind)
cudaMemcpyFromSymbol(void *dst, const void *symbol, size_t count, size_t offset, cudaMemcpyKind kind)
// 一个示例
__device__ int d_x = 1;
__device__ int d_y[2];
__global__ void kernel(void){
// 展示kernel可以直接访问
d_y[0] += d_x;
d_y[1] += d_x;
}
int main(int argc, char**argv){
int h_y[2] = {10,20};
cudaMemcpyToSymbol(d_y, h_y, sizeof(int)*2);
/*中间插入kernel函数的相关操作*/
cudaMemcpyFromSymbol(h_y, d_y, sizeof(int)*2);
}
2.3 共享内存(shared memory)
- 对于我的显卡sm_86来说,每一个SM对应的共享内存大小为100KB,每一个线程块能够拥有的最大的共享内存为99KB
- shared有仅次于register的速度(on-chip的含金量)
- 使用__shared__修饰的变量存放在shared中,可定义动态与静态两种
- 如果在单个线程块中分配过量的共享内存(想象直接给一个block分配99KB),将会限制活跃线程束的数量(只有这一个block能有足够的shared memory了)
- 访问shared memory必须加入同步机制:void __syncthreads();
- 这个函数的作用仅限于保证一个block中的线程同步,不同block是不能保证的
shared memory的主要作用:
- 减少kernel对global的访问,更加高效
- 改变全局内存访问内存的内存事务方式,提高数据访问的带宽
静态共享内存:
- 声明方式: __shared__ float tile[size,size];
- 静态共享内存的作用域随着声明位置变化:
- 1. 在kernel中声明时,静态共享内存作用域局限在这个核函数中
- 2. 在文件中,任何kernel外声明时,静态共享内存作用域对所有核函数有效
- 同静态global一样,在编译的时候就要确定内存大小
动态共享内存:
- 用类似extern __shared__ float s_array[]; 定义
- 不能使用 *s_array,不能忽略extern,不能往括号里加数
- 分配内存大小在什么地方定义:kernel<<<grid,block,nBytes>>>,这里的第三个参数用来指定动态共享内存
2.4 常量内存
- 常量内存是由全局缓存的全局内存,数量有限,大小仅为64KB。由于有缓存,线程束在读取相同的常量内存数据时,访问速度比全局内存快。
- 常量内存中的数据对同一编译单元内所有线程可见。
- 使用__constant__修饰。不能定义在kernel函数中。常量内存是静态定义的。
- 只可读,不可写
- 我们在给核函数传递数值参数时,这个变量就存放于常量内存。
- 因为常量内存本质上就是静态全局内存,因此初始化必须要使用cudaMemcpyToSymbol
- 常量内存的使用场景:当线程束中的线程从相同的内存地址中读取数据时,常量内存表现较好,因为这个过程不需要所有线程的访问,只需要读取一次并广播就可以。比如数学公式中的系数。
__constant__ float c_data; // 这个未初始化的常量内存必须用cudaMemcpyToSymbol
__constant__ float c_data2 = 6.6f; // 已经初始化,不必要使用,可以用cudaMemcpyFromSymbol在 主机端调用
float h_data = 8.8f;
// 用一个host里的float初始化常量内存中的c_data
CUDA_CHECK(cudaMemcpyToSymbol(c_data, &h_data, sizeof(float)));
__global__ void kernel_2(int N) // 这个里面的N就是存放在常量内存中,因为所有的kernel都需要访问,这样做很高效 2.5 GPU缓存
- GPU缓存:不可编程的内存(自动化这一块)
- 每个SM都有一个L1 Cache, 所有的SM共享一个L2 Cache
- L1,L2 Cache 用来存放 local memory(回忆,属于每个线程的独立的部分,本质上时global,很慢)和global memory的数据,也包括寄存器溢出的部分(回忆,溢出的部分会存到local里)
- 在GPU上只有内存加载可以被缓存,内存存储操作不能被缓存??
- 每个SM有一个只读常量缓存和只读纹理缓存,用于提升性能
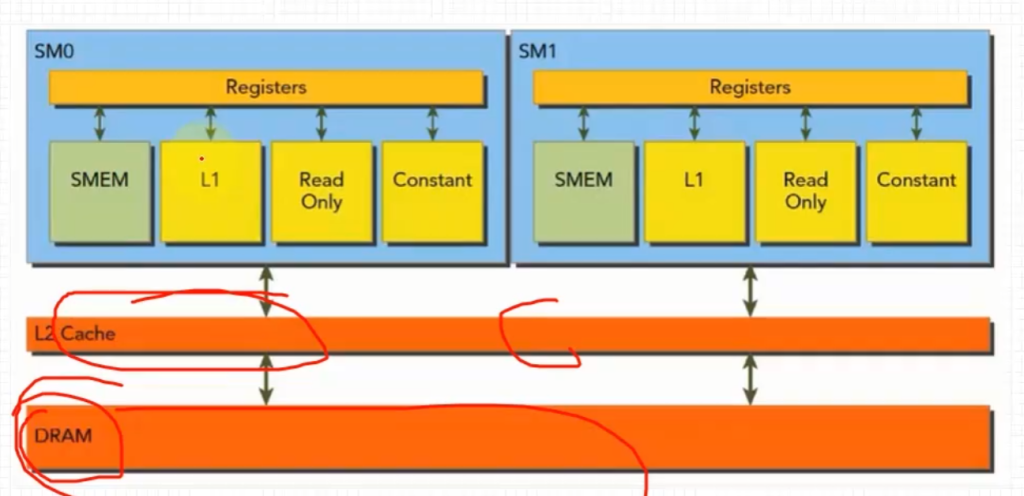
- 如图,global memory在物理上的位置在DRAM上,因此在加载全局内存数据的时候必须经过L2 Cache,但是否经过L1 Cache是可以改变的(默认不会经过L1 Cache)
L1 Cache 的查询和设置
- GPU是否支持L1缓存查询指令:cudaDeviceProp:globalL1CacheSupported
- 默认情况,数据不会缓存在统一的L1/Texture Cache中,但可以通过编译指令启用缓存:
- 开启: -Xptxas -dlcm=ca,除了带有禁用缓存修饰符的内联汇编修饰的数据外,所有读取都被缓存
- 开启: -Xptxas -fscm=ca,所有数据读取都会被缓存
L1 Cache and shared memory(以8.9为例)
- 统一数据缓存大小为128KB,包括shared memory, texture memory 和 L1 Cache
- shared memory 从统一的数据缓存中分区出来,并且可以配置为各种大小。可以设定为0,8,16,32,64和100KB。(回忆一下,一个SM对应的最大shared memory刚好是100KB,一个线程块最大能分到99KB)。这之后剩下的部分用作L1 Cache,也可以由纹理单元使用。
- 共享内存的大小可以设置,但不一定生效,GPU有自动选择最优配置的策略。
L2 Cache的一些有趣的数据:
- RTX 3060 只有3MB的 L2 Cache(sm_86)
- RTX 4070 却有36MB的 L2 Cache(sm_89), 扩展了一个数量级,减少显存带宽压力,提高能效
3. 计算资源分配
线程束本地执行上下文主要资源构成:(回忆,线程束是真正并行的,32个为一束,线程束组成线程块,因此线程块最好包含32的整数倍线程)
- 1. 程序计数器
- 2. 寄存器
- 3. 共享内存(这是线程块级别的概念,也是SM级别的概念,和L1 Cache物理上一起,128KB中最多100KB可分配)
由于SM处理的每个线程束warp计算所需的资源都是on-chip的(很显然,register,shared都很快),因此从一个执行上下文切换到另一个执行上下文是没有时间损耗的。
对于一个给定的kernel,同时存在于同一个SM中的block和warp取决于在SM中register和shared memory的分配,单个thread消耗的越多,可以存的就越少
- 对于sm_86,每个SM有64KB个register,因此如果一个thread消耗1kb,那最多只能跑2个warp
- 当然,一个thread最多只能由255个register(每个32位),所以这里就是举个例子
- 可以想象,最极端的情况,最低跑8个warp
- 同样的,对于sm_86,每个SM至多有100KB大小的shared memory。区别于register是thread级别的概念,shared是block级别的概念,但道理差不多
========== GPU Device Info ==========
Device name: NVIDIA GeForce RTX 3060 Laptop GPU
Compute capability: 8.6
SM (multiprocessor) count: 30
// 这两个数据尽可能接近最大值,才能更好的利用性能
Max threads per SM: 1536
Max resident blocks per SM: 16
L2 Cache Size: 3 MB
Global L1 Cache: Supported
Local L1 Cache: Supported
Max shared memory per SM: 100 KB
Max registers per SM: 64 K (32-bit)
Stream priorities: Supported
Memory clock rate: 7001.00 MHz
Memory bus width: 192 bits
Theoretical memory bandwidth: 336.05 GB/s当计算资源(register,shared这些)被分配给block,这个block被称为active的,warp也是这样
active warp有三种类型
- 选定的warp(active + 正在执行)
- 阻塞的warp (active + 没有做好执行的准备)
- 符合条件的warp (active + 准备好了,但还没有执行)
- 准备:32个cuda核心可用于执行 + 执行所需要的参数全部准备好
占用率 = active warp/max warp(1536/32 = 48)-> active warp/48
- 以sm_86的Nt = 1536, Nb = 16,进行一些理想的计算
- 假设并行规模足够大(总线程足够多)
- 1. 在shared和register用不满的情况下,是需要单个block含有超过96个线程,就可以满占用
- 2. register: 当真的有1536个thread,每个thread最多使用42个寄存器
- 3. shared memory: 满占用有16个block,每个block可分配100/16 = 6.25 KB的shared
- 假设有一个block需要使用超过99KB的shared,kernel无法启动
对Grid和Block设计的准则
- 1. block设计为32的倍数
- 2. block不能太小,不然由于block数量的限制,很难达到高占用
- 3. 根据kernel调整block大小(就是考虑register和shared)
- 4. block要远多于SM的数量(这里为30),也即grid要远大于这个数,保证并行足够
4. 延迟隐藏
- 指令延迟:指令从发出到完成之间的时钟周期
- 在每个时钟周期中,所有的warp调度器都有一个符合条件的warp的时候,可以达到计算资源的完全利用
- GPU的指令延迟被其他warp的计算隐藏,被称为计算隐藏(pipeline的思想,不空等)
- 指令可以分为算数指令和内存指令
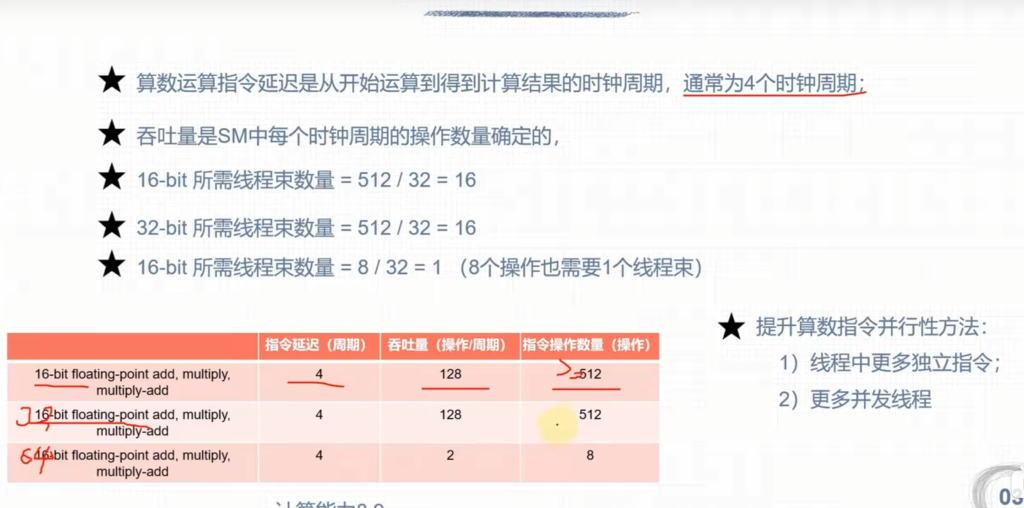
- 算数运算的指令延迟是从开始运算到得到计算结果的始终周期,通常为4
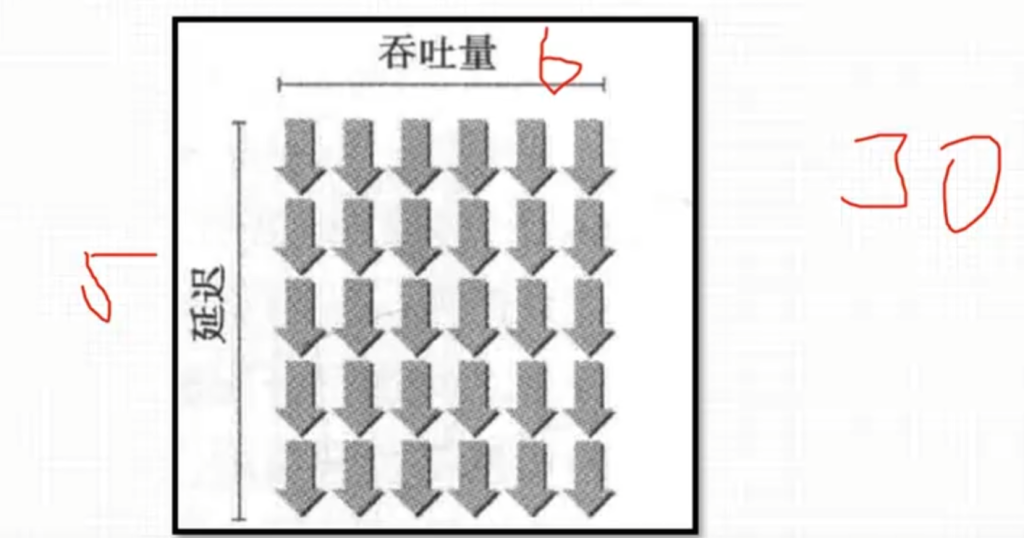
- 满足延迟隐藏的所需线程束数量:所需warp的数量 = 吞吐量 * 延迟
- 带宽和吞吐量的区别:带宽一般指理论值,吞吐量指实际达到的值
- 一些例子:
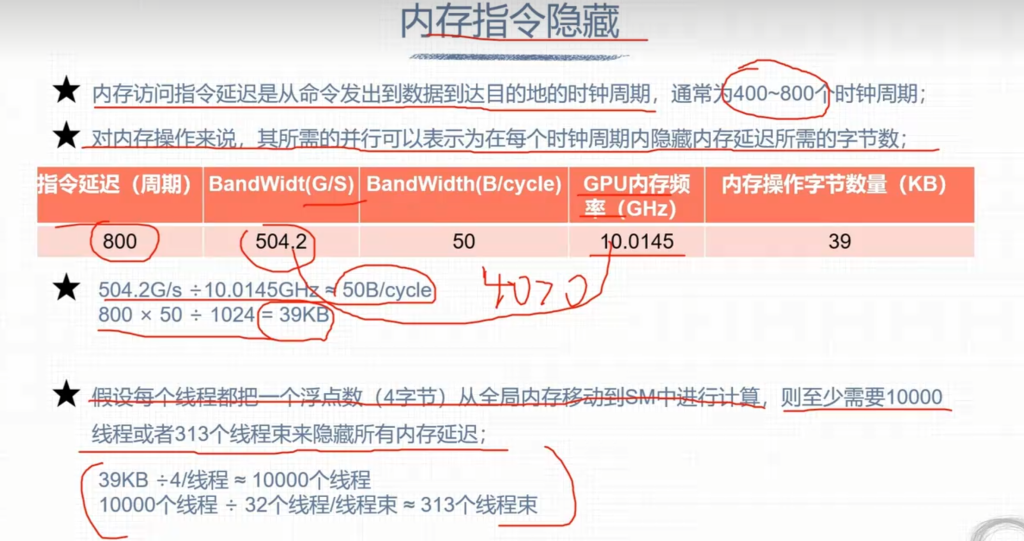
5. 线程束分化
对于一个warp,最好让里面的所有线程在同一个周期中执行相同的指令,否则就会因为分支预测机制,造成线程束分化,导致程序的并行性能下降
一个常见的解决思路是,以32为基本单位组织。因为warp分化仅仅发生在一个warp内部,因此只要保证一个warp内部执行相同的指令,就可以避免分化。
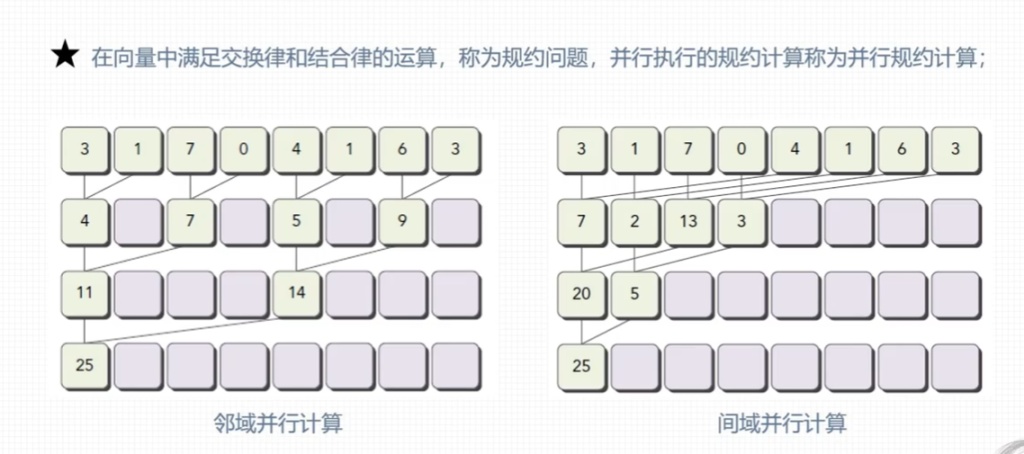
5.1 并行规约计算(分治法的思路)